Els estudis d'opinió de la Generalitat de Catalunya al vostre abast
Glossari
Accessibilitat
Propietat del web que garanteix un accés universal als usuaris, independentment del maquinari, programari, infraestructura, idioma, cultura, localització geogràfica i capacitats personals.
Agregador de continguts
Eina desenvolupada per tenir coneixement de les novetats que es produeixen en el web.
Agregar
Sumar les dades de diferents unitats petites en una unitat més gran.
Aleatori
Esdeveniment fortuït o producte de l’atzar. Un procés és aleatori quan segueix alguna distribució de probabilitat.
Anàlisi de variància ANOVA
Tècnica estadística que determina si les diferències que existeixen entre les mitjanes de tres o més grups (nivells de classificació) són estadísticament significatives. Les tècniques d’ANOVA estableixen si la variància explicada pels grups formats és suficientment més gran que la variància residual o no explicada
Banc de dades
Sistema que emmagatzema un conjunt de dades del mateix tipus de manera que ocupin el menor espai possible i es puguin actualitzar i utilitzar en qualsevol moment.
Baròmetre
També anomenat sondeig d’opinió. Estudi periòdic que té com a objectiu conèixer les opinions i actituds de la ciutadania sobre temes d’actualitat política, social i econòmica.
Biaix
Diferència entre el valor d’un paràmetre i el seu valor probabilístic esperat. És una distorsió que resta representativitat a un resultat estadístic.
CAPI
Computer Assisted Personal Interviewing. Vegeu Enquesta Telefònica Assistida per Ordinador
CATI
Computer Assisted Telephone Interviewing. Vegeu Enquesta Telefònica Assistida per Ordinador
Cens
Enquesta en la que participa tota la població.
Chi-quadrat
Vegeu Taula de contingència.
Comparació de mitjanes:
Procediment que permet calcular les mitjanes de subgrup dins les categories d’una o més variables independents.
| Sexe | Mitjana | N | Desviació típica |
| Home | 4,8126 | 1040 | 2,04987 |
| Dona | 4,8938 | 1107 | 2,07244 |
| Total | 4,8545 | 2148 | 2,06146 |
La Taula d’Anova mostra una taula d'anàlisi de variància d’un factor i calcula la significança de la variació entre els diferents grups. L’estadístic F permet conèixer si les variances dels dos grups d’observacions són o no iguals. Si la seva significança és menor a 0,05, rebutjarem la hipótesi nul.la i suposarem que la variabilitat en ambdós grups és substancialment diferent.
| Taula d'ANOVA | Suma de quadrats | gl | Mitjana quadràtica | F | Sig |
| Inter-grups (Combinades) | 3,540 | 1 | 3,540 | ,833 | ,362 |
| Intra-grups | 9119,652 | 2145 | 4,252 | ||
| Total | 9123,192 | 2146 |
Control de qualitat
Conjunt d’operacions destinades a supervisar el treball de camp des del punt de vista de la recollida de la informació (realització de l’enquesta). Concretament, inclou un conjunt de variables que permeten observar l’error de mida i l’error de no resposta.
Correlació
Mesura de la dependència lineal estadística entre dues variables. No estableix una relació de causa-efecte entre les dues variables. Es representa per r on sx, sy són les desviacions estàndards de les variables X i Y respectivament, i Sxy és la covariància mostral de X y Y.

Covariància
Xifra que mesura la variació conjunta global de dues variables. La fórmula que defineix la covariància σxy és la següent:
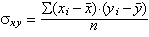
Dada (dades)
Valor(s) obtingut(s) en observar directament els resultats d’una variable en la mostra o població. Poden ser numèrics o qualitatius.
Delphi
Selecció d’una mostra d’experts o informants claus per a la investigació els quals responen un qüestionari.
Descàrrega
Transferència d’informació des del servidor de la pàgina web a l’ordinador de l’usuari.
Desviació
Diferència entre un valor i el valor mitjà o típic.
Desviació de probabilitat
Funció que indica la probabilitat que una variable aleatòria prengui un valor determinat qualsevol, o que pertanyi a un determinat conjunt de valors.
Desviació estàndard
També anomenada desviació tipus . És una mesura de distància promig dels valors observats respecte de la seva mitjana (x). Es calcula a partir del quadrat de la diferència entre cada valor i la mitjana. Un cop obtingut el promig d’aquests quadrats es fa l’arrel quadrada. Així, la desviació estàndard (σ) és l’arrel quadrada de la variància.
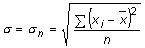
Desviació quadràtica mitjana
Vegeu Variància.
Desviació tipus
Vegeu Desviació estàndard.
Distribució de freqüències
Reducció dels valors observats que es pot representar en forma de taula, gràfic de barres o histograma. Ens diu quants elements tenen el mateix valor o cauen en el mateix interval.
Distribució normal
Distribució d’una variable aleatòria contínua que presenta una forma de campana. La mitjana cau en el centre de la distribució i la corba és simètrica respecte una línia vertical que passa per la mitjana. Els dos extrems s’estenen indefinidament, sense tocar mai l’eix horitzontal. La mitjana µ i la desviació estàndard (σ)determinen la posició i la dispersió de la distribució normal.
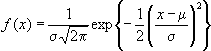
Enquesta
Mètode d’obtenció de dades d’una població o mostra a partir d’un qüestionari prèviament estructurat.
Enquesta longitudinal
Vegeu Estudi longitudinal.
Enquesta per mostreig
Enquesta en què només participa una part de la població.
Enquesta personal asssitida per ordinador
Enquestat
Persona que respon les preguntes formulades en una enquesta.
Enquesta telefònica assistida per ordinador
Mètode de codificar la informació provinent d’entrevistes telefòniques o personals directament a l’ordinador durant la entrevista. El programari conté controls de coherència interns i no permet l’entrada de codis erronis, automàticament avisa l’entrevistador dels filtres correctes.
Error
En llenguatge estadístic, diferència entre el valor observat d’una quantitat i el seu valor “real” (tot i que generalment desconegut).
Error de mida
Ocorre quan les preguntes que es fan en el qüestionari no mesuren la variable que es pretenia mesurar.
Error de no resposta
S’introdueix aquest error quan els membres de la població no responen a una enquesta.
Error de resposta
Té lloc quan les persones entrevistades no responen sincerament a la pregunta. Pot passar quan es pregunta per qüestions íntimes o controvertides.
Error de resposta voluntària
Ocorre quan una enquesta no es realitza sobre una mostra representativa, sinó que es convida a les persones a omplir qüestionari publicat en una revista, diari, etc.
Error de selecció
Es pot produir quan certs elements de la població amb determinades característiques no són inclosos en la mostra o tenen una probabilitat diferent de ser seleccionats.
Error estàndard
Indicador de la precisió d’un estimador.
Error no mostral
Són errors comesos en la selecció, recol•lecció, anotació i tabulació de les dades. Són usualment resultat d’error humà.
Estadística
En sentit general, compilació de dades sobre un objecte d’estudi determinat, o, en un sentit més específic, branca de les ciències que s’ocupa del tractament numèric sistemàtic de les dades.
Estandarització
Procés pel qual obtenim valors estàndard d’una variable X, és a dir, amb mitjana ( ) i desviació estàndard ( ) d’1. Serveix per comparar valors obtinguts de diferents distribucions. Es simbolitza per .
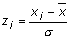
Estrat
Cadascun dels grups en què es divideix una població o una mostra que presenten trets relativament homogenis i simultàniament es diferencien dels altres grups de la població
Estudi d'opinió
Vegeu Enquesta.
Estudi longitudinal
També anomenat enquesta longitudinal o panel. És un tipus d’enquesta en la qual les mateixes persones són entrevistades en diverses ocasions en un període de temps sobre les mateixes preguntes.
Estudi transversal
En enquestes, un estudi en què les dades de cada individu s’obtenen només una vegada.
Etiqueta
Text utilitzat per descriure una variable.
Fitxa tècnica
Síntesi de les característiques principals d’un estudi: denominació, tema objecte d’estudi, objectius, unitat promotora i entitat executora, àmbit geogràfic, univers, grandària de la mostra, error mostral, dates de treball de camp, tipus de mostreig i mètode de recollida de dades.
Fitxer de freqüències
Fitxer que conté les respostes dels individus enquestats.
Freqüència
En estadística, nombre de vegades que es repeteix un determinat valor d’una variable.
Freqüència absoluta
S'anomena freqüència absoluta d'un valor Xi el nombre de vegades que es repeteix aquest.
Freqüència absoluta acumulada
S'anomena freqüència absoluta acumulada (Fi) d'un valor Xi el nombre de repeticions de valors que són més petits o iguals que ell.
Freqüència relativa
S'anomena freqüència relativa d'un valor Xi el quocient entre la freqüència absoluta fi i el nombre total de dades N.
Freqüència relativa acumulada
S'anomena freqüència relativa acumulada (Hi) d'un valor Xi el quocient entre la freqüència absoluta acumulada i el nombre total de dades.
Freqüències esperades
Freqüències que esperaríem trobar en una taula de contingència o en una distribució de freqüències si la hipòtesi nul•la fos vertadera.
Grandària de la mostra
Nombre d’elements del subconjunt de la població enquestada. La grandària de la mostra (N) està determinada per diversos criteris com el interval de confiança i el marge d’error desitjats, la variabilitat de la població, el tipus de mostreig utilitzat i els recursos econòmics disponibles.
N= 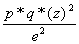
Z= Estadístic de la distribució normal estandaritzada.
p= Probabilitat que un succés ocorri.
q= Probabilitat que un succés no ocorri.
e= Nivell de confianza (normalment 0,05%)
Hipòtesi alternativa
És una afirmació sobre el valor d’un paràmetre conegut d’una població. És la hipòtesi d’investigació, el que desitgem demostrar amb l’experiment o estudi. Quan rebutgem la hipòtesi nul•la, ho fem en favor d’aquesta.
Hipòtesi nul·la
És una afirmació sobre el valor d’un paràmetre desconegut d’una població. S’assumeix com a certa fins que es demostri el contrari. Usualment indica que no hi ha canvi, que no hi ha diferència (per això es diu nul•la). Aquesta hipòtesi es rebutja o no, depenent del valor p al nivell de significança desitjat.
Índex
Variable generada a partir de la informació recollida en un estudi. Està composada per un conjunt d’indicadors que mesuren una mateixa actitud, opinió, etc.
Índex de resposta
Índex de qüestionaris retornats (que s’han respost) dins l’univers de l’enquesta.
Índex de resposta = 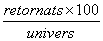
Interval
Vegeu Variable d’escala.
Interval de confiança
Indica la probabilitat que el procés seguit resulti en valors que representen vertaderament la població. En sentit probabilístic, amb un marge del 95%, podem dir que si repetíssim el procés moltes vegades, en el 95% dels casos obtindríem resultats que reflecteixen vertaderament la realitat.
Lector de continguts
Vegeu Agregador de continguts.
Marge d'error
En estadística es determina la precisió de les estimacions a partir del del marge d’error (veure error no mostral) i del interval de confiança. El marge d’error és el radi de l’interval de confiança. Per exemple, si d’una mostra es desprèn que el 50% de l’electorat prefereix que guanyi el candidat A i el marge d’error és de ± 3% i el nivell de confiança és del 95,5% (2 sigmes), el percentatge real estarà entre el 47% i el 53%, amb una confiança del 95,5%.
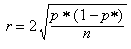
2= Número de sigmes (95,5% de confiança).
p= Probabilitat que un succés ocorri.
q= Probabilitat que un succés no ocorri.
n= Grandària de la mostra
Marginals
Vegeu Freqüència.
Matriu de dades
És una col•lecció de registres de dades.
Màxim
Valor més alt d’una distribució.
Mediana
La mediana es defineix com aquell valor que, si s'ordenen els valors de la distribució, ocupa el lloc central en aquesta ordenació. La mediana divideix la mostra en dos conjunts de la mateixa grandària, un amb valors menors o iguals que la mediana i l’altre amb valors majors o iguals a la mediana. Exemple: Observant els valors 1, 6, 5, 4, 3, 4, 5, 4, 5, el primer pas per calcular la mediana és ordenar-los: 1, 3, 4, 4, 4, 5, 5, 5, 6. Com que hi ha un total de 9 dades el valor que es troba a la cinquena posició divideix el conjunt de dades en dos grups de 4 dades: 1, 3, 4, 4, 4, 5, 5, 5, 6. Així, la mediana és 4. Quan el conjunt de dades té un nombre parell, 1, 3, 4, 4, 5, 5, 5, 6., la mediana serà la mitjana dels dos valors centrals (4 + 5)/2 = 4,5.
Metadades
Dades que descriuen altres dades, per exemple, la columna d’encapçalament en una taula, descripcions de dades, propietats, dominis, processos i mètodes. Les metadades també inclouen el nom de les variables, la seva amplada i els valors vàlids. Normalment s’emmagatzemen en un diccionari o catàleg de dades.
Microdada
Fitxers que contenen informació sobre els casos individuals de forma desagregada.
Mínim
Valor més baix d’una distribució.
Mitjana
La mitjana és el resultat de fer la suma de tots els valors observats de la variable numèrica i dividir pel nombre total d'observacions. És una mesura del valor central al voltant del qual s’ubiquen els valors mostrals d’una distribució de probabilitats.
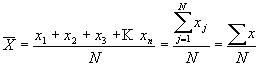
Exemple: Observant els valors 1, 6, 5, 4, 3, 4, 5, 4, 5, la seva mitjana és: (1 + 6 + 5 + 4 + 3 + 4 + 5 +4 + 5) / 9. És un paràmetre molt sensible a l'existència de valors extrems (a vegades dits anòmals o atípics) en la distribució. Per això sovint s’utilitzen altres mesures de localització com la mediana o la moda.
Moda
Freqüència més elevada. Representa el valor o valors més comuns en la població o en la mostra.
Exemple: 1, 6, 5, 4, 3, 4, 5, 5. La moda és el 5.
Exemple: 1, 3, 4, 4, 4, 5, 5, 5, 6. Les modes són el 4 i el 5.
Exemple: 1, 6, 5, 4, 3, 8, 7, 0. Aquest conjunt de dades no té moda.
Mostra
La mostra és un subconjunt representatiu de la població triat amb la finalitat d'obtenir informació sobre tot el conjunt de la població.
Mostra aleatòria
Mostra representativa
És una mostra que reflecteix les característiques de la població. La forma usual de seleccionar-la és a través d’una mostra aleatòria.
Mostra sistemàtica
Una població de grandària N es divideix entre la grandària desitjada de la mostra n per obtenir k grups diferents. Seleccionem a l’atzar un element del primer grup i començant amb aquest, seleccionem cada k-è element. És útil quan la població està disposada en algun ordre o llista, como en la guia telefònica.
Mostreig
És el procés mitjançant el qual es tria una mostra de la població.
Mostreig aleatori estratificat / Mostra aleatòria estratificada:
Sistema de mostreig que divideix la població en grups homogenis (anomenats estrats), i posteriorment s'extreu una mostra aleatòria simple de cada estrat.
Mostreig aleatori simple / Mostra aleatòria simple
Tots els elements de la població tenen la mateixa probabilitat de ser triats per formar part de la mostra.
Mostreig aleatori sistemàtic / Mostra aleatòria sistemàtica
Sistema de mostreig que selecciona a l'atzar un element de la població i a partir d'aquest element se trien els elements següents de k en k.
Mostreig estratificat per quotes / Mostra aleatòria per quotes
Sistema de mostreig que divideix la població en grups homogenis (anomenats estrats), i posteriorment s'extreu una mostra aleatòria simple de cada estrat.
Mostreig per conglomerats i àrees / Mostra per conglomerats i àrees
Sistema de mostreig que divideix la població en diferents seccions o conglomerats representatius de la població. Es trien a l'atzar unes quantes d'aquestes seccions i es prenen tots els elements de les seccions triades per formar la mostra.
Mostreig per quotes
Sistema de mostreig que garanteix que les persones entrevistades reflecteixen amb exactitud l’univers de la mostra a partir de l’aplicació de diferents quotes com ara el sexe, l’edat o la grandària del municipi. És a dir, s’estableixen les característiques del grup que es vol analitzar (per exemple, 20 individus de 25 a 40 anys de sexe femení residents a la província de Barcelona)..
N
Número de casos que té una mostra. Vegeu Grandària de la mostra.
Nivell de confiança
Veure Interval de confiança.
Nivell de significança
Probabilitat de rebutjar la hipòtesi nul•la quan és certa. Aquest nivell és seleccionat per l’investigador abans de realitzar l’experiment. Els valors més comunament seleccionats són nivells de 0,01, 0,05 i 0,10.
Observació
Valor observat d’una variable o característica d’un objecte.
Òmnibus
Reben aquesta denominació les enquestes dirigides a una mostra gran de població on cada client (públic o privat) compra un espai en el qüestionari per incloure una o vàries preguntes. En el cas d’enquestes òmnibus realitzades pel CEO es posa a disposició dels diferents departaments de la Generalitat de Catalunya un espai en el qüestionari per realitzar un únic estudi.
Onada
En un estudi o estudi longitudinal una onada és el període durant el qual la mostra (el panel) és enquestada. Normalment, un estudi panel consta de diferents onades.
Panel
Vegeu Estudi longitudinal .
Paràmetre
Es una característica mesurable que descriu una població. El seu valor normalment és desconegut.
Format de document portàtil (Portable Document Format). Format de fitxer universal que manté l’orientació de la pàgina, la tipografia i els gràfics del document original i es pot veure, imprimir i buscar amb programari de visualització com, per exemple, Adobe Acrobat.
Pes
Mesura de la contribució relativa d’una variable en les estimacions pel conjunt de la població. Quan s’utilitza una mostra, hi ha la possibilitat que algun element de la població estigui poc o massa representat. Per tal de permetre fer estimacions més precises sobre la població, s’assigna el pes a cada cas per ajustar els resultats.
Phi
Vegeu Taula de contingència.
Pla anual d'enquestes
Recull els estudis d’opinió que el Govern de la Generalitat de Catalunya té previst realitzar en el transcurs d’un any. El Pla anual del CEO es publica al DOGC.
Ponderació
Assignar a cadascun dels elements d’un conjunt un valor diferent en funció de llur importància relativa dins el conjunt.
Ponderar
Determinar el pes o valor d’un conjunt de casos.
Probabilitat
Conjunt de possibilitats que un esdeveniment ocorri o no en un moment i temps determinat. La probabilitat es mesura en una escala de 0 a 1, on el 0 indica una nul•la probabilitat que l’esdeveniment es produeixi i l’1 una certesa absoluta que l’esdeveniment ocorri.
Quotes
Vegeu Mostreig per quotes.
Rang
S'anomena rang d'una distribució estadística la diferència entre el valor màxim i el valor mínim d'aquesta.
Raó
Vegeu Variable d’escala.
Recodificar
Generar una nova variable o modificar una variable a partir de les dades recollides. Per exemple, una variable d’edat pot recollir-se en anys i recodificar-se a posteriori per produir una nova variable “amb dret a vot”, codificant amb un “1” per aquells de més de 18 anys i amb un “2” aquells menors de 18 anys.
REO
Registre d’Estudis d’Opinió. Abans RPEO.
RPEO
Registre Públic d’Estudis d’Opinió. Ara REO.
RSS
Vegeu Agregador de continguts.
Serie temporal
Observacions d’una variable feta al llarg del temps. Les sèries temporals també es poden construir a partir d’un estudi transversal o cross-section si les mateixes preguntes es repetiexen més d’una vegada al llarg del temps.
Sigma
Quan es mesura una mostra d’una població, la majoria dels resultats tendeixen a acumular-se al voltant d’un valor promig i les més allunyades de la mitjana són progressivament més escasses. Els resultats presenten una distribució normal quan les proporcions s’ubiquen simètricament a cada costat del promig. El valor del sigma (s) col.locat a l’esquerra i la dreta del promig delimita una àrea en què es troben el 68,3% els resultats de les medicions. Si el sigma es duplica, l’àrea delimitada per 2s a la dreta i -2s a l’esquerra representa el 95,54% dels resultats i l’àrea formada per 3s a la dreta i-3s a l’esquerra del promig representa el 99,74% dels resultats.
Signatura digital
Mecanisme de xifrat per autentificar informació digital que garanteix l’autenticitat i la integritat del missatge.
Significança
Mecanisme de xifrat per autentificar informació digital que garanteix l’autenticitat, la integritat i la no repudiació del missatge.
Sindicació de continguts
Procés mitjançant el qual un productor o un distribuïdor de continguts proporcionen informació en format digital a un subscriptor o a una xarxa de subscriptors.
Sondeig d'opinió
Vegeu baròmetre.
SPSS
Statistical Product and Service Solutions. Paquet estadístic que permet fer anàlisis descriptives, causals i predictives.
Taula de Contingència
Taula de dues o més variables que serveix per classificar els membres d’un grup d’acord amb determinades característiques qualitatives o quantitatives.
| Home | Dona | Total | ||
| Menys 1000€ | Absoluts | 244 | 510 | 754 |
| Freqüència esperada | 389,9 | 364,1 | 754 | |
| % de fila | 32,4 | 67,6 | 100 | |
| % de columna | 26,8 | 60,1 | 42,9 | |
| Més 1000€ | Absoluts | 665 | 339 | 1004 |
| Freqüència esperada | 519,1 | 484,9 | 1004 | |
| % de fila | 66,2 | 33,8 | 100 | |
| % de columna | 73,2 | 39,9 | 57,1 | |
| Total | Absoluts | 909 | 849 | 1758 |
| Freqüència esperada | 909 | 849 | 1758 | |
| % de fila | 51,7 | 48,3 | 100 | |
| % de columna | 100 | 100 | 100 |
A cada cel•la tenim 4 tipus de xifres. La primera correspon a les freqüències absolutes: a la mostra tenim 909 homes i 849 dones; 244 homes i 510 dones són mileuristes. La segona xifra identifica els percentatges de fila (per a cada fila, sumen 100 en la columna del total) i s’interpreten de la següent forma: més del 67% dels individus que guanyen menys de 1000€ són dones. La tercera xifra correspon als percentatges de columna. En general, quan encreuem dues variables i assignem a una d’elles el paper de variable explicativa, la comparació dels percentatges de columna ens informen sobre l’existència o no de relació entre ambdues variables. En aquest exemple, el sexe és la variable independent o explicativa i el nivell de salari és la variable dependent. Així, podem veure que el percentatge de dones que guanyen menys de 1000€ (60,1%) és major que el dels homes en aquesta situació (26,8%).
| Home | Dona | |
| Menys de 1000€ | -14,01 | 14,01 |
| Més de 1000€ | 14,01 | -14,01 |
Els residus corregits (o valors residuals) d’una taula de contingència es calculen a partir de les diferències entre les freqüències observades i les que hauríem obtingut si no hi hagués relació entre les dues variables, però es corregeixen per la grandària de les freqüències de cada categoria i per la variança de les cel.les. Tenen una distribució aproximadament normal amb una mitjana de 0 i desviació típica igual a 1. Un valor del residu corregit major que ±1,96 s’interpreta como una desviació significativa de les freqüències esperades per una cel.la determinada. En aquest cas, tenim residus superiors a ±1,96 en totes les cel.les.
Les taules de contingència tenen diferents estadístics associats. La prova de Chi-quadrat parteix de la següent pregunta: quina és la probabilitat que trobem aquestes freqüènencies (absolutes i relatives) a la mostra si no hi hagués cap relació entre les dues variables en la població? (estem fixant com a hipòtesi nul.la (H0) que no existeix associació entre el sexe i el salari). El resultat mostra que la probabilitat d’obtenir aquestes freqüències si no existís relació entre les variables és molt petita i menor a 0,05 (el llindar que convencionalment utilitzem pe rebutjar la hipòtesi nul.la). El següent pas és descobrir la força d’aquesta relació bivariable. La Phi i la V de Cramer ens informen de la magnitud i de la significança de l’associació entre les dues variables. Poden adoptar valores entre el 0 (cap associació) i l’1 (associació perfecte). La Phi només és apropiada en taules de 2 x 2 (2 categorias en cada variable). En el cas presentat aquestes mesures d’associació ens indiquen que, efectivamente, existeix una associació significativa entre sexe i salari i que la relació és força dèbil. Si la taula de contingència és de 2x2 la Phi i la V de Cramer i coincideixen.
| Valor | gl | Significança | |
| Chi-quadrat | 197,8762 | 1 | 0,000 |
| Valor | Significança | |
| Phi | -0,3355 | 0,000 |
| V de Cramer | 0,3355 | 0,000 |
Treball de camp
Recollida de la informació d’un estudi.
Univers
Conjunt format per tots els individus que formen part de la població que es vol analitzar. Per exemple, en un estudi electoral, l’univers, la població de referència, està format només pels individus amb dret de vot i, per tant, s’exclouen els estrangers i els menors de 18 anys.
Valors perduts
Els valors o casos perduts (o missing) s’assignen quan la informació recollida no apareix, el que pot passar per vàries raons – entre elles, quan la persona es nega a contestar o la pregunta no era aplicable per a aquella persona a causa de respostes anteriors.
Variable
Característica analitzada d’un element de la població o mostra (per exemple, edat de la persona, ingressos de la família, índex de preus al consum) que pot assumir diferents valors. Pot ser quantitativa (variable numèrica) o qualitativa (variable alfanumèrica).
Variable alfanumèrica
Variable amb valores emmagatzemats com a cadenes de caràcters i que no poden utilitzar-se en operacions aritmètiques. Aquests caràcters poden ser alfabètics, numèrics o caràcters especials. També reben el nom de variables de cadena.
Variable contínua
Vegeu Variable nominal.
Variable d'escala
Variable de cadena
Vegeu Variable alfanumèrica.
Variable depenent
Variable que adquireix un valor en funció de una o més variables (independents). En un estudi es tracta de la variable que volem explicar.
Variable dicotòmica
Aquella variable que només té dues opcions de resposta.
Variable discreta
Variable que disposa de més de dues opcions de resposta. És una variable que pot assumir un número comptable de diversos valors.
Variable dummy
Variable recodificada (vegeu Recodificar) mitjançant una assignació d’un valor 1 ó 0 a un subjecte, depenent de si presenta o no una determinada característica.
Variable explicativa
Vegeu Variable independent.
Variable independent
Variable que pot explicar o predir el comportament d’una altra variable. També anomenada variable explicativa
Variable nominal
Variable de tipus qualitatiu i no contínua que mitjançant caràcters identifiquen categories o tipus de resposta. Els valors de les dades representen categories sense un ordre intrínsec (per exemple, categoria laboral). Podem trobar valors de cadena (alfanumèrics) o numèrics que representen diferents categories (per exemple: 1 = home, 2 = dona).
Variable numèrica
Variable que té números com a valors. Veure variables discretes o variables nominals.
Variable ordinal
Variable de tipus qualitatiu o quantitatiu i no contínua que mitjançant números identifica categories amb un ordre natural. Els valors de les dades representen categories amb un cert ordre intrínsec (per exemple: baix, mitjà, alt; totalment d’acord, en desacord, totalment en desacord). Les variables ordinals poden ser valors de cadena (alfanumèrics) o numèrics (1 = baix, 2 = mitjà, 3 = alt).
Variància
Mesura de la dispersió d’una variable aleatòria respecte al seu valor mitjà. Ens informa de la variabilitat d’un conjunt de dades. És un promig dels quadrats de les diferències dels punts o dades respecte la seva mitjana. També s'anomena desviació quadràtica mitjana. Es representa per S²x.
V de Cramer
Vegeu la Taula de contingència



